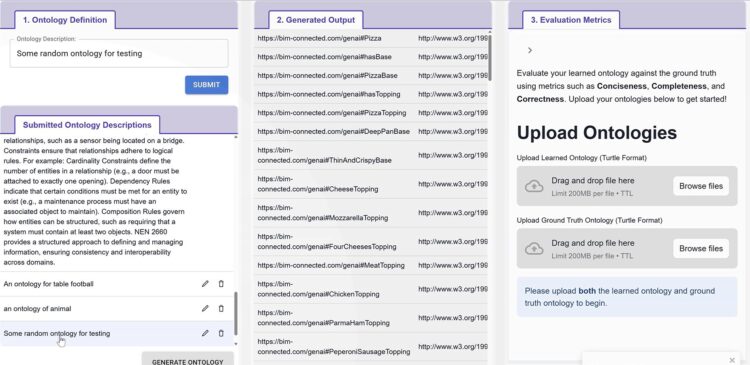
Large Language Models (LLM’s) om lerende ontologieen te ondersteunen
Bij 𝗕𝗜𝗠-𝗖𝗼𝗻𝗻𝗲𝗰𝘁𝗲𝗱 onderzoeken we voortdurend hoe geavanceerde technologie kan helpen bij het structureren, verbinden en begrijpen van informatie. Een van onze nieuwste interne experimenten? 𝗟𝗮𝗿𝗴𝗲 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗠𝗼𝗱𝗲𝗹𝘀 (𝗟𝗟𝗠’𝘀) gebruiken ter ondersteuning van 𝗼𝗻𝘁𝗼𝗹𝗼𝗴𝘆 𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴.
🔧 De afgelopen maanden hebben we:
– Een veelbelovende academische benadering geselecteerd uit recent onderzoek,
– Pipelines opgezet om experimenten uit te voeren met 𝗿𝗲𝗮𝗹 𝗶𝗻𝗱𝘂𝘀𝘁𝗿𝘆 𝘀𝘁𝗮𝗻𝗱𝗮𝗿𝗱𝘀 zoals 𝗡𝗘𝗡 𝟮𝟲𝟲𝟬 en 𝗜𝗠𝗕𝗢𝗥,
– Verschillende modellen en promptmethoden getest (OpenAI, Mistral, DeepSeek, Spacy),
– Een prototype-app gemaakt om ontologieën te extraheren uit beschrijvingen in natuurlijke taal,
– En begonnen met de integratie met ons eigen platform, Wistor.
We hebben dit behandeld als een 𝗲𝘅𝗽𝗲𝗿𝗶𝗺𝗲𝗻𝘁𝗮𝗹 𝗶𝗻𝗻𝗼𝘃𝗮𝘁𝗶𝗼𝗻 𝘁𝗿𝗮𝗰𝗸 – een brug tussen onderzoek en praktische BIM-gebruiksscenario’s. Het resultaat is een 𝘄𝗼𝗿𝗸𝗶𝗻𝗴 𝗽𝗿𝗼𝗼𝗳-𝗼𝗳-𝗰𝗼𝗻𝗰𝗲𝗽𝘁 die laat zien hoe we semantische technologieën dichter bij dagelijkse workflows kunnen brengen.
Dit soort initiatieven weerspiegelen wie we zijn als bedrijf: altijd nieuwsgierig, altijd aan het experimenteren en altijd gericht op het omzetten van complexe ideeën in praktische oplossingen.
💡Wat is de volgende stap? We denken nu na over hoe we dit verder kunnen brengen: betere criteria, meer use cases en een bredere toegankelijkheid. We blijven hier de komende tijd aan werken.